OpenAI 在 6 月放出一個很搶眼的說法:新模型寫的健康答案,比醫師親手寫的還好。它說 GPT-5.5 Instant 在五項評比裡,全面勝過 GPT-4o 與醫師親手寫的答案。這句話很容易讓人立刻選邊站,一邊喊 AI 要取代醫師了,一邊罵這是行銷話術。但我想先把焦點從分數上移開。真正該記住的數字不是它贏了幾項,是每週已經有超過 2.3 億人拿 ChatGPT 問健康與保健問題。這 2.3 億人問完之後,誰來把關、什麼時候該回到醫師,才是會真正影響到人的地方。跑分高不高,是其次。
先看 OpenAI 到底測了什麼
把它宣稱的數字攤開來,確實漂亮。OpenAI 說 GPT-5.5 Instant 在準確、清楚、完整等五個評比面向上,分數都高過醫師寫的答案,指令遵循最高到 89.9%,而且過去兩個月被標記至少一個事實問題的健康回答比率,降了 71%。參與評測的是來自 60 個國家、超過 260 位醫師,他們累計審過逾 70 萬則模型回覆。光看陣仗,這不是隨手做做的測試。
問題不在數字漂不漂亮,在這個分數該怎麼讀。一個健康答案的好壞,能不能用這種方式量出來,比量出來幾分更值得想清楚。

這個分數的方法論陷阱
看到任何「贏過醫師」的自評,先問三件事:誰當裁判、題庫怎麼選、測的跟真實差多遠。
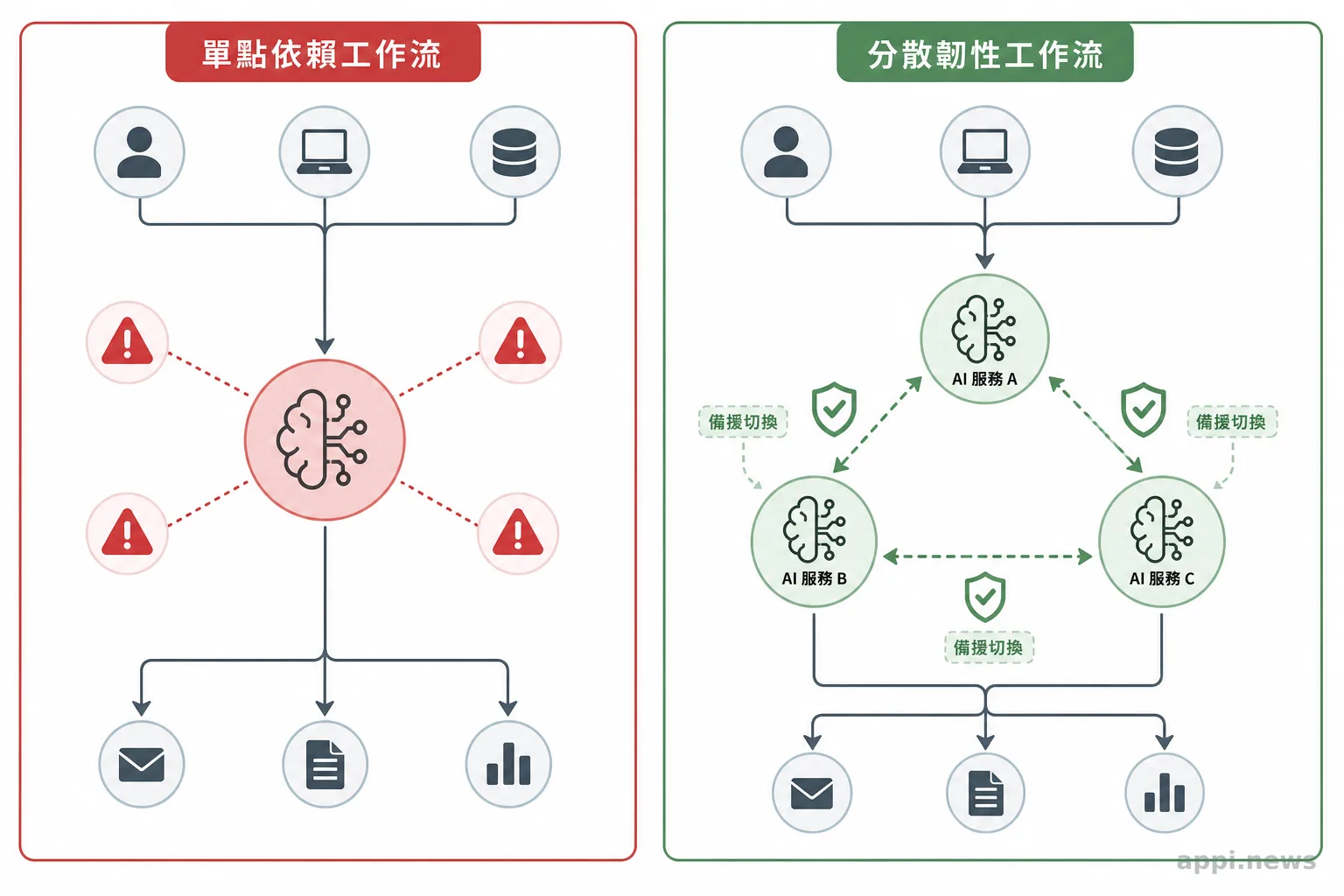
裁判這關,要看清楚。這些評測全是 OpenAI 在自家內部跑的,沒有任何結果公開給外部審查,等於它自己出題、自己改考卷、自己宣布成績。題庫這關也一樣,醫師是在約 3,500 則回覆上,拿模型答案去比醫師在有充足時間、可以上網查的情況下寫出來的答案。這是在「寫一段文字答案」這件事上比高下,不是在「真的看一個病人、做出正確處置」上比。
第三件事最關鍵:測試情境跟診間的真實落差有多大。一篇評析 HealthBench 這類健康評測的研究就直接點破,在 benchmark 上表現好,不保證能轉成更準的診斷、更好的流程或更高的病人安全;在 HealthBench 拿高分,不等於臨床決策做得好。自評本身不是造假,但它測得到的,本來就只是模型「會不會寫出一段看起來對的答案」,不是它在真實病人面前做不做得對。

這會不會就是 Evaluation Gap
講一段我自己的判斷。我看到這種自評,第一個反應就是:這準嗎?會不會就是 Evaluation Gap(評測落差)?因為這剛好是現在 AI 最大的問題。一個模型可以在 benchmark 上拿 95 分,丟進真實世界卻只剩 75 分。
醫療這個落差更明顯。我先前寫過,OpenAI 自己用真實對話重放來測模型時就發現,模型認得出標準安全測試的比率高到近乎滿分,換成真實生產對話卻只剩個位數,這正說明 benchmark 沒辦法可靠預測模型在真實情境裡的表現與風險。這也是我一直在講的同一件事,可信度靠的是落地設計,不是模型本身的強弱。一個自評分數再高,後面沒有驗證機制接住它,分數就只是分數。
重點講三次:AI 取代的不是醫師,而是 Google 搜尋
有一句話我想講三次,因為它決定了你該怎麼看這整件事。
AI 取代的不是醫師,而是 Google 搜尋。
AI 取代的不是醫師,而是 Google 搜尋。
AI 取代的不是醫師,而是 Google 搜尋。
過去身體不舒服,多數人的第一步是打開搜尋引擎輸入症狀,在一堆內容農場跟論壇裡自己拼湊。現在這一步換成了問 ChatGPT。每週 2.3 億人在做的,本質上是「查」這個動作的升級,不是「看診」這個動作的取代。看清楚這件事,風險的位置就清楚了。AI 比 Google 強,是因為它把散落的資訊整理成一段話;但它跟 Google 一樣,給你的是資訊,不是診斷。
我之前寫過,LLM 在健康場景最有用的地方,是幫你補上「你不知道自己該問的問題」,讓你帶著更完整的問題清單去看醫師,而不是讓它替醫師下判斷。OpenAI 自己的條款也寫得很清楚,這工具不用於任何疾病的診斷或治療。一個比 Google 好用很多的健康搜尋,這個定位其實剛剛好。

AI 健康答案怎麼讀:四層判讀框架
既然它是更強的搜尋,那就需要一套讀法。我用一個簡單的框架,把一個 AI 健康答案拆成四層:
- 第一層,知識正確。它講的醫學知識本身對不對。
- 第二層,適用於這個病人。對的知識,套到你的年齡、病史、正在吃的藥上,還成不成立。
- 第三層,知道自己不知道。資訊不足時,它會不會老實說「這我不確定」,而不是硬擠一個聽起來很篤定的答案。
- 第四層,知道什麼時候該轉給醫師。該叫你去急診、該面對面檢查的時候,它會不會明確把你推回醫療系統。
OpenAI 的自評,分數主要落在第一、二層。它也宣稱新版在察覺何時需要緊急就醫、以及不誇大信心地說明不確定上有進步,這對應到第三、四層。但這兩層恰恰最難量,也最難只靠自評證明。前兩層是知識題,題庫測得出來;後兩層是判斷題,要在真實、資訊不全的情況下做對。真正難的,是後面兩層,而那正是評測落差最容易咬人的地方。

一般人與診所怎麼用,何時該回到醫師
給一般人的用法很簡單:把 AI 的健康答案當成升級版的搜尋,拿它整理問題、列出該追問的點,但把第三、四層的判斷權留給自己跟醫師。出現這幾種情況就直接回到醫師,不要再跟它盧下去:症狀急、會痛、變化快;答案要你停藥、改藥或自行用藥;你問到第二、三輪它開始反覆或閃躲。帶著它幫你整理出來的問題清單去門診,是它目前最務實的用法。
給診所與醫療機構的話,重點不是要不要用,是先想清楚誰來驗、在哪一步驗。可信度靠的是落地流程,不是模型多強。把 AI 答案定位成衛教與初步整理,明確標出哪些情境不交給它、哪一關一定要真人或獨立第三方把關。順序不能倒,先定義它在你的流程裡負責哪一段,再決定開放到哪。一個自評贏過醫師的模型,落地的價值上限,仍然是由你怎麼接住它決定的。

常見問題
問:GPT-5.5 Instant 的健康答案真的比醫師好嗎?
答:OpenAI 自評說它在五項評比勝過醫師寫的答案、指令遵循達 89.9%,但這些結果全在它自家內部跑、未公開外審,比的也是「寫一段文字答案」而不是真實看診。把它當參考,不要當定論。
問:那我可以直接用 ChatGPT 看病嗎?
答:不行。OpenAI 條款明寫它不用於疾病的診斷或治療。比較準確的理解是,它取代的是你以前用 Google 查健康那一步,給的是資訊不是診斷;急症、用藥調整、症狀變化快的時候,一律回到醫師。
問:什麼是 Evaluation Gap,為什麼醫療特別要在意?
答:評測落差指模型在 benchmark 上分數漂亮,到真實情境卻明顯掉漆。研究指出在 HealthBench 拿高分,不保證臨床決策做得好。醫療因為資訊不全、後果重,這個落差更明顯,所以分數越高,越要回頭看落地有沒有驗證機制接住它。
參考來源
- ChatGPT's new health upgrade beats doctor-written answers, OpenAI says(The Decoder)GPT-5.5 Instant 在五項評比勝過 GPT-4o 與醫師寫的答案、指令遵循達 89.9%、錯誤率降 71%、60 國逾 260 位醫師審過逾 70 萬則回覆
- OpenAI Brings Improved Health Responses To Free ChatGPT(Search Engine Journal)結果全在 OpenAI 自家內部跑、未公開給外部審查,醫師在約 3,500 則回覆上比較模型與醫師寫的答案;面對與其他 AI 健康答案相同的量測落差
- OpenAI unveils ChatGPT Health, says 230 million users ask about health each week(TechCrunch)每週逾 2.3 億人在 ChatGPT 問健康與保健問題;OpenAI 條款明載工具不用於任何疾病的診斷或治療
- HealthBench: Advancing AI evaluation in healthcare, but not yet clinically ready(PMC / npj Digital Medicine)benchmark 表現好不保證轉成更準診斷、更好流程或更高病人安全;在 HealthBench 拿高分不等於臨床決策做得好