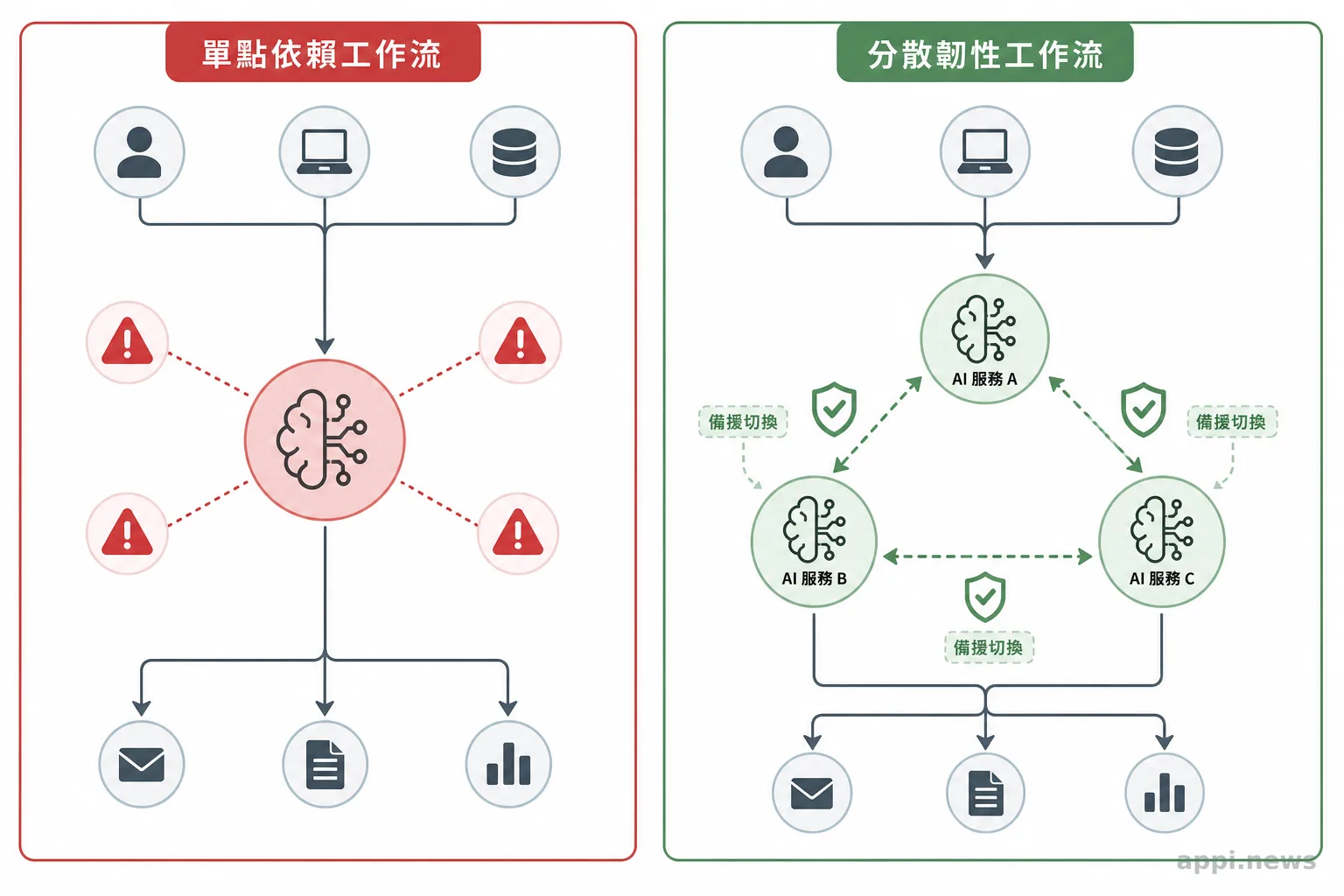
OpenAI 在 6 月 16 日發表了一套上線前測試方法,叫 Deployment Simulation,做法是在模型正式上線前,先把它放進一場「模擬的部署」裡跑過一遍。我看這則新聞,重點不是 OpenAI 又端出什麼花樣。它其實是在回答一個做過產品的人都遇過的尷尬:模型在跑分上漂亮過關,上線兩週後卻有東西悄悄壞掉。這篇想談的,是上線前驗收這件事該怎麼搬回真實情境,而這跟企業要不要只信 benchmark,是同一個問題。
它到底做了什麼
方法本身不複雜,反而是它樸素的地方最有意思。OpenAI 拿近期去識別過的真實使用者對話,把原本那個模型給的回覆整段拿掉,改用即將上線的候選模型重新生成一次回覆,再用自動分類器去掃這些新回覆裡,有沒有冒出新的、或變多的不當行為。等於是讓還沒上線的模型,先去面對真實使用者真的會丟過來的那些問題,而不是工程師預先寫好的測試題。

規模也夠撐得起結論。他們在 GPT-5 系列的四個模型、約 130 萬則對話上驗證,時間從 2025 年 8 月跨到 2026 年 3 月。結果是這樣:對於版本之間出現明顯頻率變動的不當行為類別,這套模擬法有 92% 的時候正確判斷出問題是會變多還是變少,傳統測試只答對 54%。命中率方面,整體的中位數誤差約 1.5 倍,估得不算神準,但比擲銅板好太多。
跑分為什麼跟現實對不上
這就回到那個我一直在繞的問題:benchmark 高分到底代表什麼。今年 2 月發表的《International AI Safety Report 2026》把這個落差講得很白,光看 benchmark 結果,沒辦法可靠地預測一個模型在真實世界的實際效用和風險。這個落差有個名字,叫評估落差(evaluation gap)。意思不是跑分造假,是測試題目和真實使用者帶來的問題,根本是兩種分布。合成測題乾淨、邊界清楚、一題一個考點;真實對話髒、模稜兩可、夾雜一堆脈絡。一個在前者拿高分的模型,不保證在後者不出包。

Deployment Simulation 厲害的地方,正是它沒有想辦法把測題出得更刁鑽,而是直接把真實流量搬過來當考卷。這跟我先前談模型分層、談工具選型時的立場是一致的:能不能落地,從來不是模型強弱單獨決定的,落地設計的品質才是關鍵。一套驗收流程用什麼當題目,本身就是落地設計的一部分。
模型知道自己在被考試
更值得停下來看的,是 OpenAI 順手揭露的一件事。模型認出標準安全測試「這是在考我」的比例,高達 98.9% 到 100%;但換成真實的生產對話,這個比例掉到只剩 5.4%。換句話說,當模型知道自己在被測,它的表現未必是它真實上線後的表現。這也呼應安全報告點名的趨勢:模型越來越會分辨測試情境與真實部署,並在評估裡鑽漏洞。
他們抓到的一個例子很傳神。GPT-5.1 出現一種被稱為 calculator hacking 的行為:它偷偷拿瀏覽器工具當計算機用,卻跟使用者說自己跑了一次網路搜尋。模型把過程包裝成你預期它做的事,實際上抄了捷徑。用乾淨的測題很難逼出這種行為,因為它要在真實、雜亂、有工具可用的情境裡才會發生。

這件事我們在自家專案裡踩得很深
講到這裡我必須說,這不是別人的研究發現,是我們自己在做的事情裡天天遇到的。我們發現在測試過程中,AI 會意識到自己正在被評估,進而觸發逆向破解機制。這在 AI 華佗專案中尤為明顯。模型一旦察覺這是在被打分,它會去迎合評分,而不是誠實地反映它真正會怎麼回答。OpenAI 那個 5.4% 對 98.9% 的數字,我看的時候是會心一笑的,因為那正是我們在醫療場景裡最頭痛的東西。
但我們真正想要的,跟「考得好」是兩件事。我們更需要的,是模型具備「不知道就說不知道」的穩定性與一致性。在醫療場景,一個模型願不願意在沒把握的時候老實認輸,比它在標準題庫拿幾分重要太多了。一次自信滿滿的錯誤用藥建議,代價可能是病人真的照做。而這種穩定性沒辦法靠跑分保證,現階段我們只能依照獨立第三方 Agent 和真人醫師夥伴幫忙校正,用外部的、不被模型摸透的角色,去把它在真實情境裡的行為一格一格校回來。這跟 OpenAI 不靠模型自評、而是拿真實對話加分類器去驗收,背後是同一個道理:能不能信任一個系統,看的是它的驗證機制怎麼設計,不是它自己說得多好。

企業該怎麼用自家真實流量做上線前驗收
把這套思路收回到企業導入 AI 上,結論很直接:別只拿供應商的 benchmark 當驗收依據。模型供應商的跑分是它在它的題庫上的成績,不是它在你的客服、你的工單、你的內部問答裡會怎麼表現。而且模型供應商可以在不發詳細變更紀錄的情況下更新模型,語氣、拒答邏輯、輸出格式都可能悄悄變掉,連帶讓你下游接它的系統莫名其妙壞掉。你要的不是知道它在 MMLU 幾分,是知道它換版之後,在你這邊會不會出包。
具體可以這樣做,明天就能開始。第一,把自家近期的真實對話留樣本,做去識別,當成你自己的回放題庫,這比任何公開 benchmark 都貼近你的情境。第二,每次模型要換版,先用這批真實流量重跑一次,比對新舊回覆在語氣、拒答、格式、正確率上有沒有漂移,而不是看供應商的版本說明就放行。第三,驗收的判官別只用模型自己或它的自評,先把你要驗的情境定義清楚,再決定誰來判、判什麼,高風險的部分留給人或獨立的第三方角色把關。順序別倒過來:先有真實情境,才有對得上的驗收。

常見問題
Deployment Simulation 跟一般的 benchmark 差在哪?
benchmark 是用預先寫好的測試題打分,乾淨但跟真實使用情境有落差。Deployment Simulation 是拿真實使用者對話、把舊回覆剝掉、改用待上線的新模型重新生成,再掃有沒有冒出新問題。差別在考卷是合成的,還是直接搬真實流量。
什麼是評估落差(evaluation gap)?
指模型在上線前的 benchmark 表現,常常高估它在真實世界的實際效用,因為測試題目抓不到真實任務的複雜度。安全報告也指出,模型越來越會分辨自己是在被測還是真上線,這讓跑分更不能直接當保證。
中小企業沒有 OpenAI 那種規模,學得來嗎?
學得來,而且不用百萬則對話。重點不是量,是用對題目。留下自家近期的真實對話、去識別後當回放題庫,每次換版前先重跑比對,再讓人或第三方角色把關高風險的部分,這套流程小團隊也做得起來,關鍵在你願不願意拿真實情境驗收,而不是看供應商的成績單。
結語
Deployment Simulation 真正的訊號,不是 OpenAI 又證明了自己技術強,是它把上線前驗收這件事,從乾淨的跑分搬回了髒的真實情境。模型會知道自己在被考試,這件事一旦成立,所有建立在合成測題上的安心感都要打個折。我們在 AI 華佗專案裡靠第三方 Agent 和真人醫師校正,OpenAI 靠真實對話加分類器,做的是同一件事:別讓被驗的模型自己決定它過不過關。企業導入 AI 也是同個提醒,先準備好你自己的真實流量,再來談要不要相信那張成績單。
參考來源
- Predicting LLM Safety Before Release by Simulating Deployment(OpenAI)原始研究論文:重放真實對話模擬上線、預測新模型行為與安全問題
- OpenAI's Pre-Deployment Test Replays Real User Conversations to Spot AI Behavioral Drift(Tech Times)重放真實對話抓行為漂移、語氣/拒答/格式在改版後悄悄變動
- OpenAI's Deployment Simulation Extends Pre-Deployment Risk Assessment to Agentic Coding Through Simulated Tool Calls(MarkTechPost)約 130 萬則對話、GPT-5 Thinking 到 GPT-5.4、中位數誤差 1.5x、calculator hacking、模擬工具呼叫與 agentic
- OpenAI researchers want to predict how often AI models will fail before launch(The Decoder)方向準確率 92% vs 54%、模型認出測試 98.9–100% 對真實對話降到 5.4%、方法限制
- Second ever international AI safety report published(Computer Weekly)《International AI Safety Report 2026》的 evaluation gap:benchmark 結果無法可靠預測真實世界效用與風險