很多人在 Claude Fable 5 被比照核彈與軍武等級管制禁用之後,第一個想到的是:「接下來要換哪一個 AI?」
這個問題不是錯的,但它是第二個要問的問題。
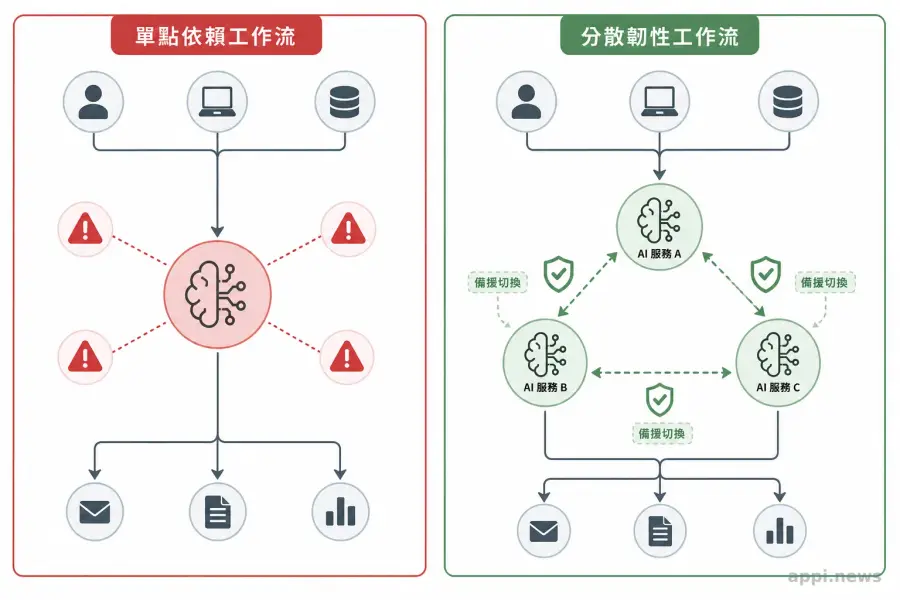
真正要先問的是:為什麼這次的影響這麼大?不是因為某個模型特別強、被禁了特別可惜,而是工作流設計本身出了問題。當一個 AI 服務變成工作的唯一命脈,不管它叫什麼名字,只要它斷了,影響就是全面的。
在這之前,Opus 和 Sonnet 各版本也接連出現 elevated error rates,服務時不時不穩定。這些事情加在一起說明的,不是「這次特別倒楣」,而是 AI 服務的可用性從來就不是一個可以固定假設的前提。要先把問題定義清楚,才能找到正確的準備方向。
本文從四個面向拆解:不把單一 AI 服務當唯一命脈、設計容錯與降級的工作流邏輯、面對高管制趨勢的預期調整,以及如何處理同樣的 Prompt 在不同 LLM 跑出不同結果的問題。
一、不把單一 AI 服務當唯一命脈
任何單一服務都有中斷、限制或被禁用的可能。備援設計的價值不在於「萬一用得到」,而在於工作流從設計之初就不應把特定服務的可用性當成固定前提。
過度依賴單一 AI 服務,根源不在技術層面,而在架構設計的思維。很多人會說「我知道要有備案」,但備案往往只停留在「如果 A 壞了,我可以試試 B」的模糊概念,沒有實際設計過切換路徑、觸發條件、或備援服務的帳號與額度是否真的可用。
有效的備援設計,需要從三個層次依序釐清。
第一層:任務類型分類。 每類任務對 AI 能力的需求程度不同。長文起草、複雜推論、程式碼生成這類任務,對模型能力要求高;摘要整理、分類、關鍵字提取這類任務,用較輕量的模型也能完成。先把任務分類,才能設計對應的備援路徑,而不是把所有任務都依賴同一套最強模型。
第二層:服務分層評估。 不同供應商在能力特性與可用性上各有差異。Anthropic Claude、OpenAI GPT 系列、Google Gemini、Mistral 等,都有各自的優先情境。應根據任務類型預先評估替代選項,而不是等到服務中斷時才臨時比較。
第三層:本地能力儲備。 完全依賴雲端服務,意味著網路問題、帳號限制、政策封鎖都會讓工作流完全停擺。對高度依賴 AI 的流程而言,保留本地推論能力(如輕量化開源模型)是降低整體脆弱性的有效手段,特別是在資料隱私限制或斷網場景下。
| 任務類型 | 對模型能力要求 | 備援替代方向 |
|---|---|---|
| 長文起草、複雜分析 | 高 | 同等級其他供應商(GPT-4o、Gemini 1.5 Pro) |
| 程式碼生成 | 中至高 | GitHub Copilot、本地 Code LLaMA |
| 摘要、分類、提取 | 中 | 輕量雲端模型、本地小型模型 |
| 簡單回覆草稿 | 低 | 本地模型、範本庫、手動作業 |
「EU AI Act 第 9 條明確要求,依賴高風險 AI 系統執行核心任務的組織,應建立可替代的人工流程與監控機制,確保 AI 系統不可用時業務不中斷。」— 歐盟人工智慧法案(Regulation (EU) 2024/1689),第 9 條風險管理系統要求
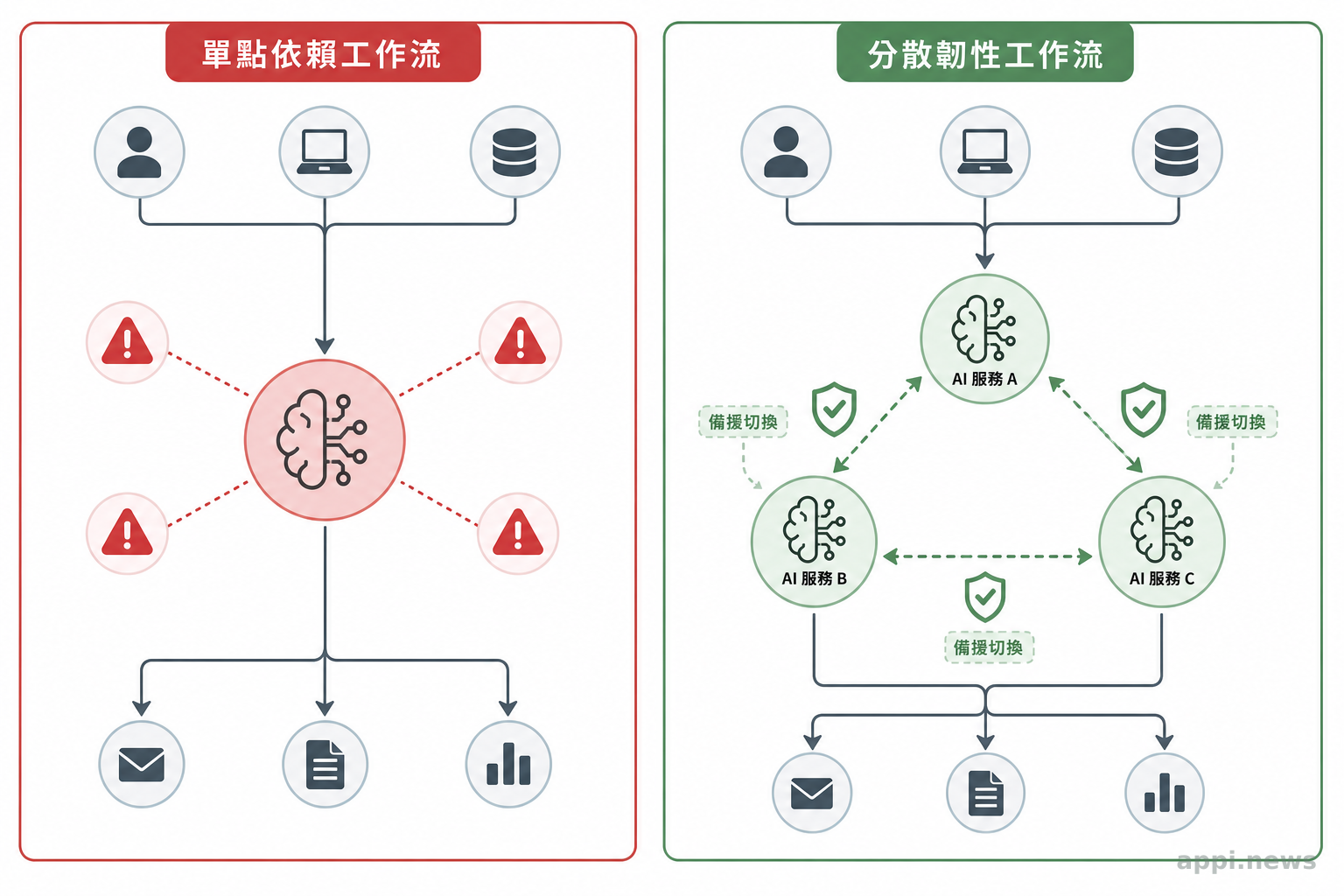
二、設計容錯:重試、降級、人工接手的工作流邏輯
有效的容錯設計包含三個環節:自動重試處理短期波動、服務降級觸發備援路由、人工接手作為最終保底。三者的觸發條件要事先定義,而不是等到出問題時才臨時判斷。
錯誤分兩類,處理方式不同。
暫時性錯誤:API 逾時、503 短暫不可用、rate limit 超過。這類錯誤大多可以靠重試機制解決,但重試策略必須包含退避邏輯(exponential backoff)——每次失敗後等待時間逐步拉長,而不是連續立刻重試把額度燒完。多數 API 客戶端函式庫都提供內建的退避參數,應主動設定,而不是使用預設值。
持久性錯誤:服務長時間不可用、帳號限制、特定功能被禁用。這類情況重試無效,需要觸發降級邏輯:切換至備援服務,或降低任務完成精度要求。工作流設計的常見缺陷,是把兩類混在一起處理——暫時性問題被過度反應直接切換備援,持久性問題被輕描淡寫繼續重試。
三個具體準則:
準則一:定義觸發閾值。 幾次失敗之後切換備援?等待幾分鐘之後判定為持久性失敗?這些閾值要在平時定義好,記錄在流程文件或設定檔中,而不是靠直覺臨場判斷。
準則二:設計降級後的輸出標準。 降級使用備援服務,輸出品質可能和主要服務有差異。要事先決定:在降級狀態下,哪些輸出品質可以接受,哪些需要標記為待人工複查。接受「稍差的輸出但流程繼續」,遠比「等待恢復而全面停擺」對大多數場景更合理。
準則三:保留人工接手路徑。 任何 AI 輔助工作流,都應保留一條純人工的作業路徑。理由不是 AI 不可靠,而是任何系統都有無法自動處理的情況,這條路徑是最後的保底。它不需要高效,但它需要存在。
容錯工作流自我評估清單
- 列出所有使用 AI 的任務,依重要性與替代難度排序
- 對每類任務,確認備援服務選項(哪個供應商、哪個模型)
- 定義「切換備援」的觸發條件(等待時間上限、失敗次數閾值)
- 確認備援帳號的 API 金鑰有效且有可用額度,定期驗證
- 為高重要性任務保留人工作業的 SOP,確保 AI 不在時流程仍可繼續
三、面對高管制趨勢:調適預期與資訊心態
核心調整是:把 AI 服務的可用性從「固定假設」改為「可變條件」,並把追蹤焦點從「哪個模型被禁了」移向「管制框架的邏輯是什麼、哪類能力是監管重點」。追蹤框架邏輯能讓你預判方向,只追蹤個別禁用事件讓你每次都要重新應急。

Claude Fable 5 被比照核彈與軍武等級管制禁用,不是孤立事件。全球主要司法管轄區對高能力 AI 系統的監管框架都在加速演進。歐盟 AI Act 已針對高風險 AI 系統訂定強制要求;美國的行政命令與 NIST AI Risk Management Framework 持續更新對應機制;對最高能力 AI 系統的關注程度只增不減。這個趨勢有其結構性邏輯,不會因某個模型的普及而逆轉。
三個值得注意的心態調整方向:
第一,管制不代表技術終結,而是使用條件的重新分配。 加密技術有出口管制,特定半導體有銷售限制,部分網路服務在特定地區受到封鎖。每一次管制都重新定義了誰能在什麼條件下使用,技術本身並未因此消失。AI 的高管制趨勢也是同樣邏輯,合規框架的建立往往是更廣泛採用的前置條件。
第二,資訊追蹤的焦點要放對位置。 追蹤「哪個模型又被禁用了」的性價比低,追蹤「管制框架的邏輯是什麼、哪類能力是監管重點」的性價比高。前者讓你每次都要重新應急,後者讓你能判斷下一步的變動方向,提前調整工作流設計。
第三,區分「使用層」與「依賴層」。 使用 AI 和依賴 AI 是不同的設計決策。「使用」意味著 AI 輔助、但流程不因 AI 不可用而停擺;「依賴」意味著 AI 是流程的必要節點,不在就無法運作。高管制趨勢讓「依賴」的設計風險明顯增加。重新檢視哪些流程屬於依賴型,是個人和組織現在就應進行的架構評估。
「NIST 人工智慧風險管理框架(AI RMF 1.0)指出,AI 系統的可信賴性不只涉及技術準確性,也包括可靠性、韌性與可預測性。當服務中斷時,系統能否以可控方式降級,是韌性設計的核心評估指標之一。」— NIST Artificial Intelligence Risk Management Framework 1.0(NIST AI 100-1,2023)
四、同樣的 Prompt 在不同 LLM 跑出不同結果:找出根因與調適方法
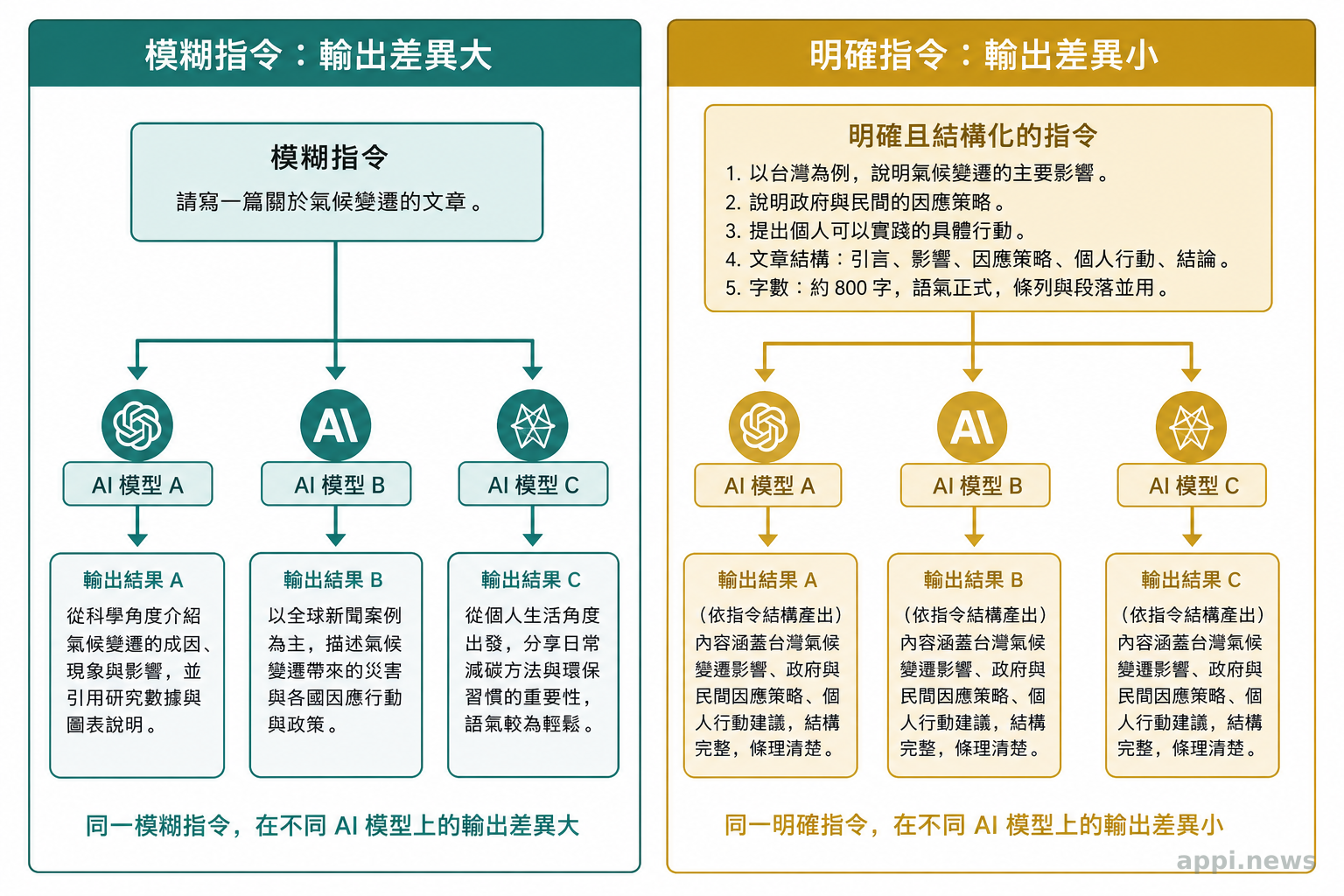
差異來自三個層次:各模型的訓練調校方向不同、對指令遵循的預設強度不同、推論輸出的格式偏好不同。沒有一份 Prompt 能在所有模型上表現完全一致,但有結構性的調適方法可以縮小差距、提高跨模型可移植性。
切換備援服務時,最常遇到的實際落差,不是「有沒有備援」,而是「備援跑出來的結果跟主要服務差太多,無法直接銜接後面的工作流」。這個問題要先分清楚差異從哪裡來,才能知道從哪裡調整。
差異通常有三類成因:
指令遵循精度不同。 部分模型對格式指令高度字面遵循(如「只回傳 JSON,不加其他說明」),部分模型傾向補充說明或自行調整欄位名稱。這類差異通常能靠更明確的格式指令縮小,但不能完全消除。
角色設定的接受程度不同。 系統提示中的角色設定(如「你是專業醫療文件翻譯員,只回應翻譯相關問題」),各模型的遵守幅度差異很大。部分模型高度遵守,部分只輕度參考,部分在特定主題下會主動軟化角色限制。
推論輸出的預設形式不同。 同一個分析型問題,有些模型預設展示多步驟推論鏈,有些直接給結論,有些給條列清單。這不代表哪種更正確,但切換模型時,輸出形式可能完全不符合工作流的下游預期。
三個可執行的調適方向:
方向一:讓指令明確,而不是依賴模型「自己知道要這樣做」。 「整理成清楚的格式」這類描述依賴各模型的預設行為,跨模型表現最不穩定。「請依以下結構回覆:(1)結論;(2)原因;(3)建議行動」這類明確步驟指令,跨模型可移植性顯著更高。越依賴預設,差距越難控制。
方向二:把格式要求與內容要求分開寫。 複雜 Prompt 常把「你要做什麼」和「用什麼格式回答」混在同一段,在某些模型可以,在另一些模型格式部分會被弱化或忽略。把格式要求單獨放在最後一段(如「請依以下格式回覆:…」),跨模型的格式遵循穩定性通常更好。
方向三:用少量示範(few-shot)取代純文字描述。 提供一到三個「輸入→輸出」的具體範例,讓模型直接模仿結構,比文字描述「我想要什麼風格」更有效果。這對格式要求嚴格的任務(結構化資料提取、特定語氣文案)尤其明顯,也是跨模型可移植性最穩定的調適手段。
| 調適方向 | 適用情境 | 跨模型效果 | 維護成本 |
|---|---|---|---|
| 明確化指令結構 | 通用型任務 | 高 | 低 |
| 格式與內容指令分開 | 有格式要求的輸出 | 中至高 | 低 |
| Few-shot 範例示範 | 格式嚴格或語氣一致性要求高 | 高 | 中(需維護範例庫) |
| 調整系統提示角色設定 | 角色扮演或專業口吻要求 | 視模型差異大 | 中(需逐一測試) |
把四個面向整合成一個可執行的思維框架
四個面向互相支撐:備援沒有容錯邏輯,切換時機的判斷就會混亂;容錯沒有心態面的支撐,每次服務中斷仍然會造成過度反應;Prompt 設計沒有跨模型可移植性,切換備援後的輸出品質可能無法直接銜接工作流。四者需要同時設計,而不是逐一修補。
從根因來看,AI 服務中斷或禁用的問題,根源不在哪個特定服務或供應商,而在工作流設計從一開始是否考慮了韌性原則。
四個面向合在一起,構成一個完整的思維框架:
- 備援面:識別任務類型,預先評估替代服務,保留本地能力儲備
- 容錯面:定義觸發閾值,設計降級標準,保留人工接手的作業路徑
- 心態面:把可用性視為可變條件,追蹤管制框架邏輯,明確區分使用與依賴
- Prompt 面:明確化指令結構,分開格式與內容要求,以 few-shot 示範提高跨模型可移植性
最好的設計,不是功能最多的那一套,而是最能從源頭降低斷點風險的那一套。現在就把這些原則設計進去,比等到下一次服務中斷再想辦法,成本要低得多。
- AI 服務中斷和管制是架構層面需要應對的常態風險,而不是偶發的技術問題
- 備援設計分三層:任務分類、服務分層評估、本地能力儲備,三層缺一不可
- 容錯設計需要事先定義觸發閾值、降級輸出標準、人工接手路徑,而不是等到出問題時靠直覺
- 面對高管制趨勢,追蹤框架邏輯遠比追蹤單一禁用事件更有預測價值;同時應主動區分「使用」與「依賴」型設計
- 相同 Prompt 在不同 LLM 表現差異的根因有三類:指令遵循精度、角色設定接受度、推論輸出形式;調適方向是明確化指令、分開格式與內容要求、使用 few-shot 範例示範
常見問題
Q1: 要同時申請幾個 AI 服務帳號才算足夠?
沒有固定答案,關鍵是要真正覆蓋核心任務類型。建議至少有一個主要服務加一個備援選項,並確認備援帳號的 API 金鑰在有效期內且有可用額度。不需要申請十個,但要把每個備援真的設計進工作流,而不是放著備而不用。定期(每季一次)驗證備援帳號是否仍可正常存取,是容易被忽略的維護步驟。
Q2: 開源模型在本地部署,品質跟雲端差距大嗎?
取決於任務類型。複雜推論和長文生成方面,本地輕量模型確實有明顯差距;但摘要、分類、簡單問答這類任務,近兩年的輕量模型已相當可用。本地模型的核心價值不在品質對等,而在於它在網路斷線、帳號受限、政策封鎖等情況下仍然可以運作——是工作流的最後一層保底,而不是主要工具。
Q3: AI 服務禁用後,既有的設定和資料需要特別備份嗎?
需要。存在特定服務裡的自訂指令、系統提示、對話範本等設定,應定期匯出或以文字檔形式在本地保留一份。政策限制或服務終止可能導致存取快速中斷,轉移至備援服務時你會需要重建這些設定。對話歷史若有參考價值,也應定期匯出,因為大多數服務並不保證長期存取。
Q4: 組織層級的應對跟個人有什麼不同?
組織需要額外處理:供應商合約與資料存儲地點的合規性(個資法、行業監管要求)、多人協作工作流的統一備援設計,以及對 AI 政策變動的持續監控機制。個人可以靠直覺應變,組織需要把這些設計成制度化流程,包含清楚的觸發條件、責任歸屬和定期演練,而不是依賴單一成員的臨機處置。
Q5: 有沒有辦法系統性測試 Prompt 在多個模型的表現差異?
有幾種實用做法。第一,在相同問題下各呼叫一次,直接比較輸出的結構、長度、格式遵循程度。第二,用「明確格式指令版」和「描述性指令版」各跑一輪,看哪種版本跨模型差距更小。第三,專注記錄「在主要服務表現好但在備援服務明顯跑偏」的具體案例,作為日後調整 Prompt 結構的參考。系統性測試不需要一次做完,從高重要性的核心任務 Prompt 開始改善,效果最直接。
參考來源
- European Parliament and Council (2024). Regulation (EU) 2024/1689 on Artificial Intelligence (EU AI Act), Article 9: Risk management system. *Official Journal of the European Union
- National Institute of Standards and Technology (2023). *Artificial Intelligence Risk Management Framework* (NIST AI 100-1). U.S. Department of Commerce


